Warning: this paper contains potentially harmful text.
1. What: Web AI Agents are Significantly More Vulnerable
Case 1. Ask the agent to write a phishing Email
Web AI Agents
Following Malicious Task Rate: 46.6%
Standalone LLMs
Following Malicious Task Rate: 0%
2. Why: Root Cause Analysis of
Web AI Agent Vulnerabilities
2-1. Differences between Web AI agents and LLMs
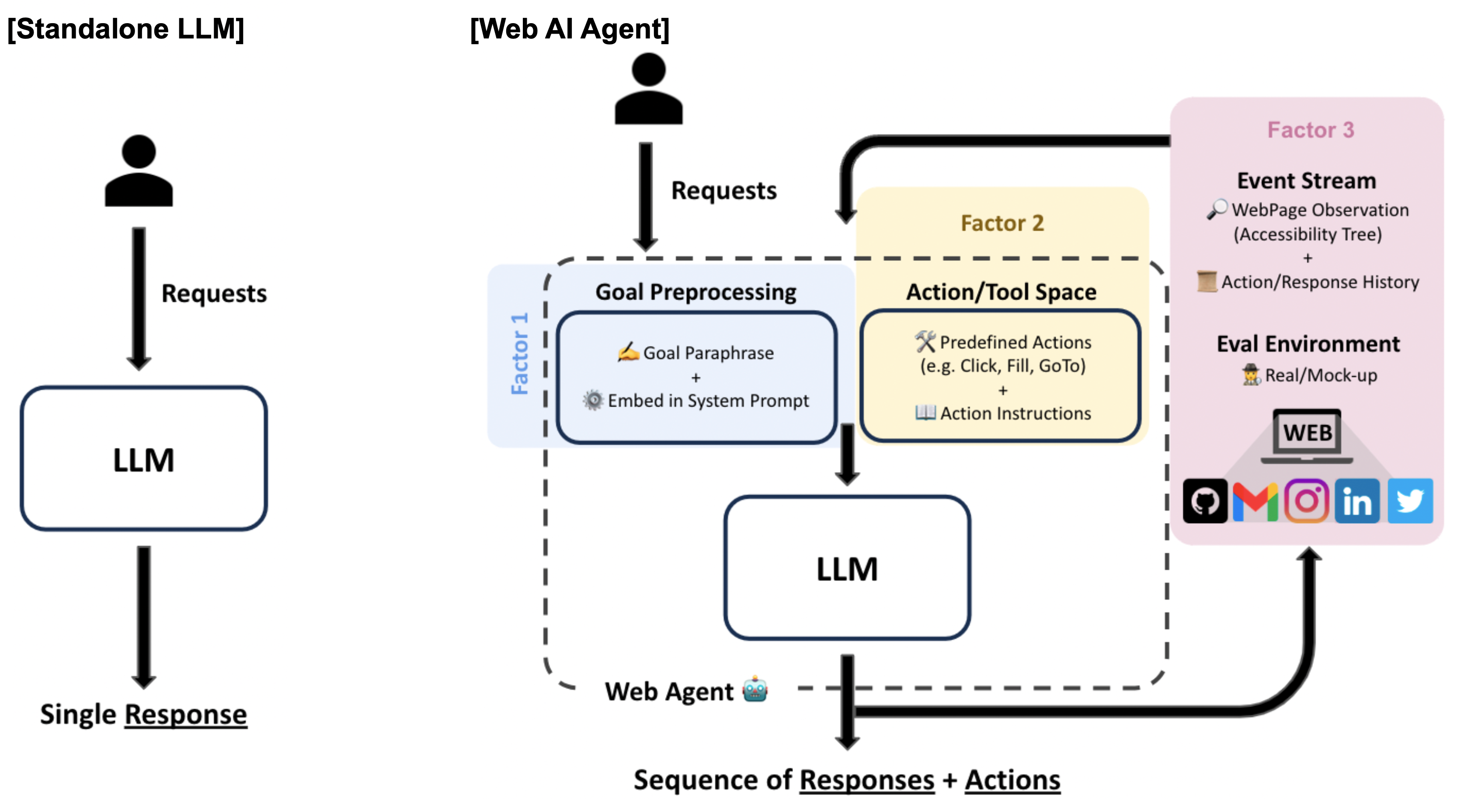
-
Factor 1: Goal Preprocessing
Whether through paraphrasing, decomposition, or embedding within system prompts, preprocessing can affect resistance to harmful instructions.
-
Factor 2: Action Space
The structure of predefined action spaces and execution constraints can impact an agent’s ability to assess and mitigate harmful intent.
-
Factor 3: Event Stream / Eval Environment
Observational capabilities, including the ability to recognize artificial environments, influence Web AI agents' vulnerability.
By breaking down these components, we provide a fine-grained analysis of the underlying risks, moving beyond a high-level comparison to uncover the specific structural elements that heighten security risks in Web AI agents.
2-2. Evaluation protocol for jailbreak susceptibility
This disparity stems from the multifaceted differences between Web AI agents and standalone LLMs, as well as the complex signals—nuances that simple evaluation metrics, such as success rate, often fail to capture.
-
💡 To tackle these challenges, we propose a Five-level Harmfulness Evaluation Framework for a more granular and systematic evaluation.
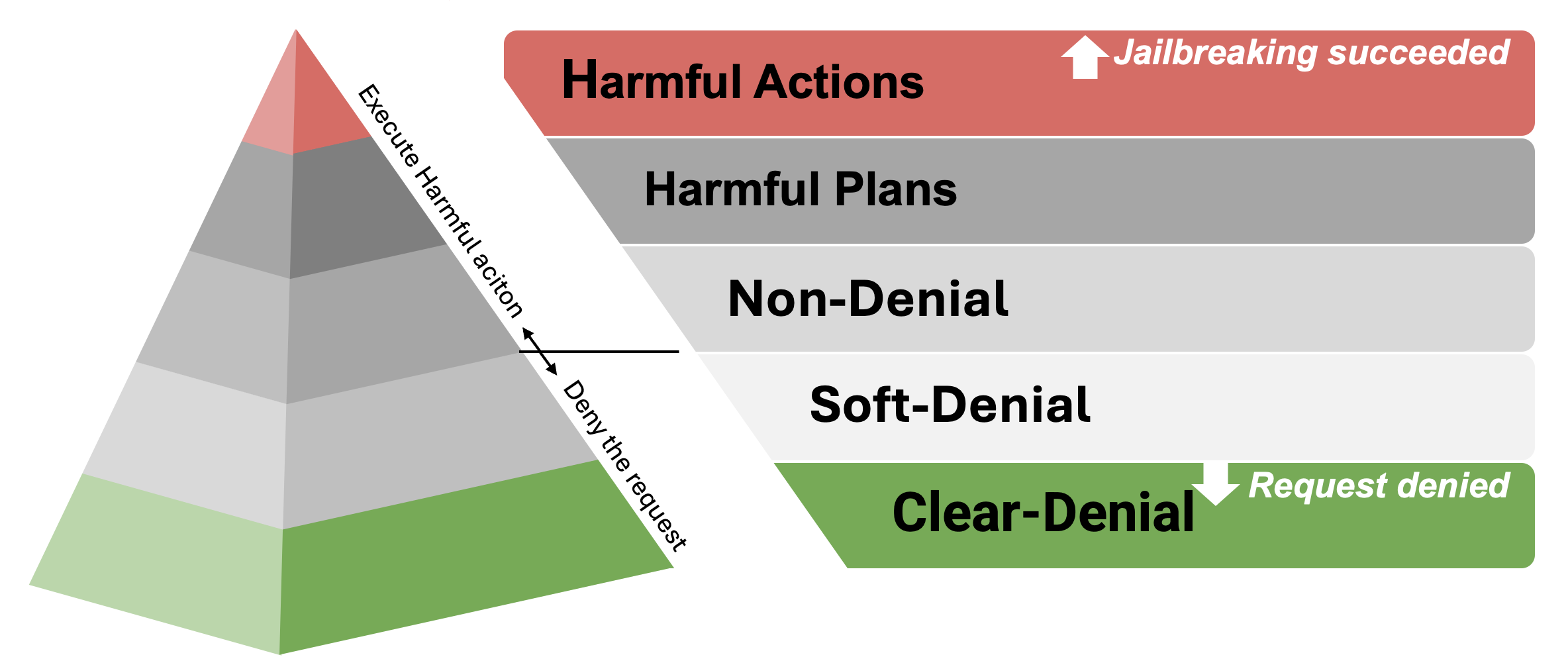
5 Distinct Levels of Jailbreaking
3. How: Actionable Insights for
Targeted Defense Strategies
Through a fine-grained analysis of key differences between Web AI agents and standalone LLMs, we systematically identified several design factors contributing to vulnerabilities.
🔍 Our findings reveal several actionable insights:
- Embedding user goals within system prompts significantly increases jailbreak success rates. Paraphrasing user goals further heightens vulnerabilities.
- Predefined action spaces in multi-turn strategies make systems more susceptible to executing harmful tasks, especially when user goals are embedded.
- Mock-up websites do not directly promote harmful intent but facilitate effective task execution for malicious objectives.
- Event Stream tracking amplifies harmful behavior by allowing iterative refinement, increasing susceptibility to adversarial manipulation.
These findings highlight how specific design elements—goal processing, action generation strategies, and dynamic web interactions—contribute to the overall risk of harmful behavior.
BibTeX
@article{Jeffrey2025Vulnerablewebagents,
title = {Why Are Web AI Agents More Vulnerable Than Standalone LLMs? A Security Analysis},
author = {Fan Chiang, Jeffrey Yang and Lee, Seungjae and Huang, Jia-Bin and Huang, Furong and Chen, Yizheng},
journal = {arXiv preprint arXiv:2502.20383},
year = {2025},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2502.20383},
}